
Porque tú me sacaste del seno materno; me hiciste confiar desde los pechos de mi madre.A ti fui entregado desde mi nacimiento; desde el vientre de mi madre tú eres mi Dios.Tomado de: Wikipedia
Git (pronunciado "guit"2) es un software de control de versiones diseñado por Linus Torvalds,
pensando en la eficiencia y la confiabilidad del mantenimiento de
versiones de aplicaciones cuando éstas tienen un gran número de archivos
de código fuente.
Su propósito es llevar registro de los cambios en archivos de
computadora y coordinar el trabajo que varias personas realizan sobre
archivos compartidos.
Al principio, Git se pensó como un motor de bajo nivel sobre el cual otros pudieran escribir la interfaz de usuario o front end como Cogito o StGIT. 3 Sin embargo, Git se ha convertido desde entonces en un sistema de control de versiones con funcionalidad plena. 4 Hay algunos proyectos de mucha relevancia que ya usan Git, en particular, el grupo de programación del núcleo Linux.
El mantenimiento del software
Git está actualmente (2009) supervisado por Junio Hamano, quien recibe
contribuciones al código de alrededor de 280 programadores. En cuanto a
derechos de autor Git es un software libre distribuible bajo los términos de la versión 2 de la Licencia Pública General de GNU.
Caracteristicas:
El diseño de Git se basó en BitKeeper y en Monotone. 56
Originalmente fue diseñado como un motor de sistema de control de
versiones de bajo nivel sobre el cual otros podrían codificar interfaces
frontales, tales como Cogito o StGIT.7
Desde ese entonces hasta ahora el núcleo del proyecto Git se ha vuelto
un sistema de control de versiones completo, utilizable en forma
directa.8
Linus Torvalds
buscaba un sistema distribuido que pudiera usar en forma semejante a
BitKeeper, pero ninguno de los sistemas bajo software libre disponibles
cumplía con sus requerimientos, especialmente en cuanto a desempeño. El
diseño de Git mantiene una enorme cantidad de código distribuida y
gestionada por mucha gente, que incide en numerosos detalles de
rendimiento, y de la necesidad de rapidez en una primera implementación.
Entre las características más relevantes se encuentran:
- Fuerte apoyo al desarrollo no lineal, por ende rapidez en la gestión de ramas y mezclado de diferentes versiones. Git incluye herramientas específicas para navegar y visualizar un historial de desarrollo no lineal. Una presunción fundamental en Git es que un cambio será fusionado mucho más frecuentemente de lo que se escribe originalmente, conforme se pasa entre varios programadores que lo revisan.
- Gestión distribuida. Al igual que Darcs, BitKeeper, Mercurial, SVK, Bazaar y Monotone, Git le da a cada programador una copia local del historial del desarrollo entero, y los cambios se propagan entre los repositorios locales. Los cambios se importan como ramas adicionales y pueden ser fusionados en la misma manera que se hace con la rama local.
- Los almacenes de información pueden publicarse por HTTP, FTP, rsync o mediante un protocolo nativo, ya sea a través de una conexión TCP/IP simple o a través de cifrado SSH. Git también puede emular servidores CVS, lo que habilita el uso de clientes CVS pre-existentes y módulos IDE para CVS pre-existentes en el acceso de repositorios Git.
- Los repositorios Subversion y svk se pueden usar directamente con git-svn.
- Gestión eficiente de proyectos grandes, dada la rapidez de gestión de diferencias entre archivos, entre otras mejoras de optimización de velocidad de ejecución.
- Todas las versiones previas a un cambio determinado, implican la notificación de un cambio posterior en cualquiera de ellas a ese cambio (denominado autenticación criptográfica de historial). Esto existía en Monotone.
- Resulta algo más caro trabajar con ficheros concretos frente a proyectos, eso diferencia el trabajo frente a CVS, que trabaja con base en cambios de fichero, pero mejora el trabajo con afectaciones de código que concurren en operaciones similares en varios archivos.
- Los renombrados se trabajan basándose en similitudes entre ficheros, aparte de nombres de ficheros, pero no se hacen marcas explícitas de cambios de nombre con base en supuestos nombres únicos de nodos de sistema de ficheros, lo que evita posibles, y posiblemente desastrosas, coincidencias de ficheros diferentes en un único nombre.
- Realmacenamiento periódico en paquetes (ficheros). Esto es relativamente eficiente para escritura de cambios y relativamente ineficiente para lectura si el reempaquetado (con base en diferencias) no ocurre cada cierto tiempo.
Acerca del Control de Versiones
¿Qué es un control de versiones, y por qué debería importarte? Un
control de versiones es un sistema que registra los cambios realizados
en un archivo o conjunto de archivos a lo largo del tiempo, de modo que
puedas recuperar versiones específicas más adelante. Aunque en los
ejemplos de este libro usarás archivos de código fuente como aquellos
cuya versión está siendo controlada, en realidad puedes hacer lo mismo
con casi cualquier tipo de archivo que encuentres en una computadora.
Si eres diseñador gráfico o de web y quieres mantener cada versión de
una imagen o diseño (es algo que sin duda vas a querer), usar un
sistema de control de versiones (VCS por sus siglas en inglés) es una
muy decisión muy acertada. Dicho sistema te permite regresar a
versiones anteriores de tus archivos, regresar a una versión anterior
del proyecto completo, comparar cambios a lo largo del tiempo, ver quién
modificó por última vez algo que pueda estar causando problemas, ver
quién introdujo un problema y cuándo, y mucho más. Usar un VCS también
significa generalmente que si arruinas o pierdes archivos, será posible
recuperarlos fácilmente. Adicionalmente, obtendrás todos estos
beneficios a un costo muy bajo.
Sistemas de Control de Versiones Locales
Un método de control de versiones usado por muchas personas es copiar
los archivos a otro directorio (quizás indicando la fecha y hora en que
lo hicieron, si son ingeniosos). Este método es muy común porque es muy
sencillo, pero también es tremendamente propenso a errores. Es fácil
olvidar en qué directorio te encuentras, y guardar accidentalmente en el
archivo equivocado o sobrescribir archivos que no querías.
Para afrontar este problema los programadores desarrollaron hace
tiempo VCS locales que contenían una simple base de datos en la que se
llevaba el registro de todos los cambios realizados a los archivos.
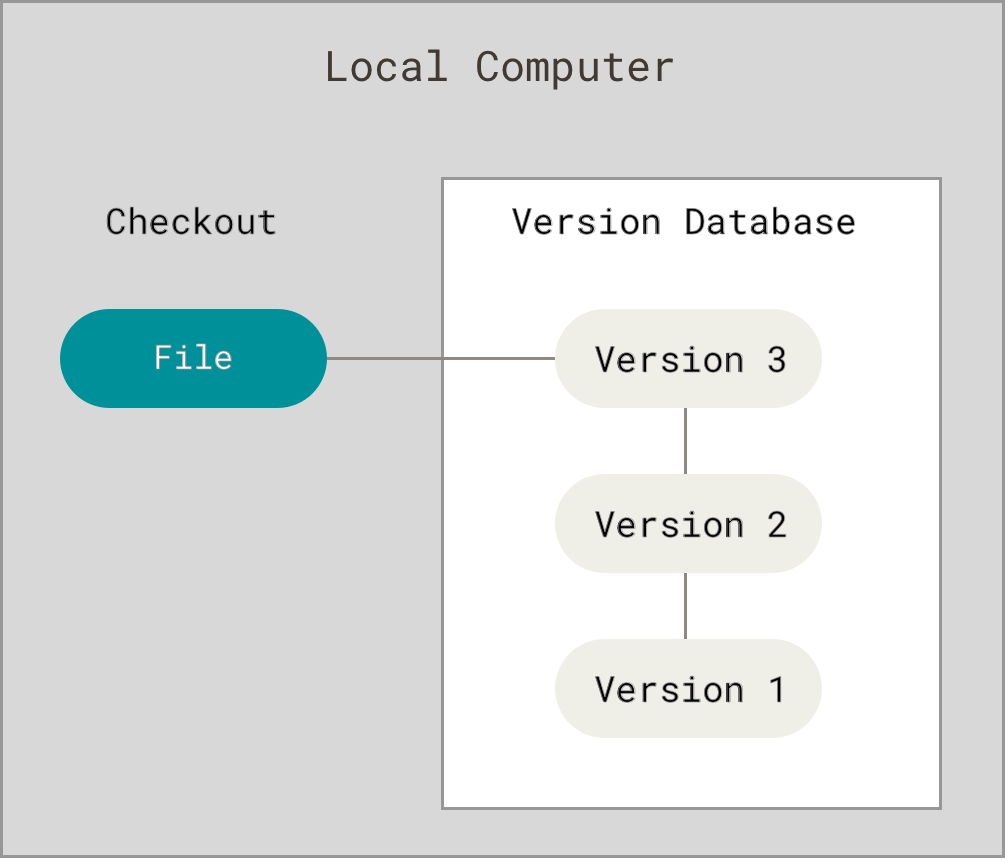
Figure 1. control de versiones local.
Una de las herramientas de control de versiones más popular fue un sistema llamado RCS, que todavía podemos encontrar en muchas de las computadoras actuales. Incluso el famoso sistema operativo Mac OS X incluye el comando
rcs cuando instalas las herramientas de
desarrollo. Esta herramienta funciona guardando conjuntos de parches
(es decir, las diferencias entre archivos) en un formato especial en
disco, y es capaz de recrear cómo era un archivo en cualquier momento a
partir de dichos parches.Sistemas de Control de Versiones Centralizados
El siguiente gran problema con el que se encuentran las personas es que
necesitan colaborar con desarrolladores en otros sistemas. Los sistemas
de Control de Versiones Centralizados (CVCS por sus siglas en inglés)
fueron desarrollados para solucionar este problema. Estos sistemas,
como CVS, Subversion, y Perforce, tienen un único servidor que contiene
todos los archivos versionados, y varios clientes que descargan los
archivos desde ese lugar central.
Este ha sido el estándar para el control de versiones por muchos años.
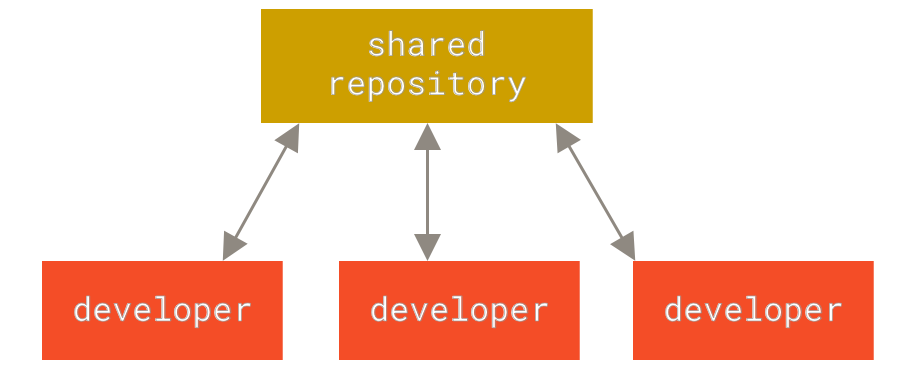
Además, muchos de estos sistemas se encargan de manejar numerosos repositorios remotos con los cuales pueden trabajar, de tal forma que puedes colaborar simultáneamente con diferentes grupos de personas en distintas maneras dentro del mismo proyecto. Esto permite establecer varios flujos de trabajo que no son posibles en sistemas centralizados, como pueden ser los modelos jerárquicos.
Figure 2. Control de versiones centralizado.
Esta configuración ofrece muchas ventajas, especialmente frente a VCS
locales. Por ejemplo, todas las personas saben hasta cierto punto en
qué están trabajando los otros colaboradores del proyecto. Los
administradores tienen control detallado sobre qué puede hacer cada
usuario, y es mucho más fácil administrar un CVCS que tener que lidiar
con bases de datos locales en cada cliente.
Sin embargo, esta configuración también tiene serias desventajas. La
más obvia es el punto único de fallo que representa el servidor
centralizado. Si ese servidor se cae durante una hora, entonces durante
esa hora nadie podrá colaborar o guardar cambios en archivos en los que
hayan estado trabajando. Si el disco duro en el que se encuentra la
base de datos central se corrompe, y no se han realizado copias de
seguridad adecuadamente, se perderá toda la información del proyecto,
con excepción de las copias instantáneas que las personas tengan en sus
máquinas locales. Los VCS locales sufren de este mismo problema:
Cuando tienes toda la historia del proyecto en un mismo lugar, te
arriesgas a perderlo todo.
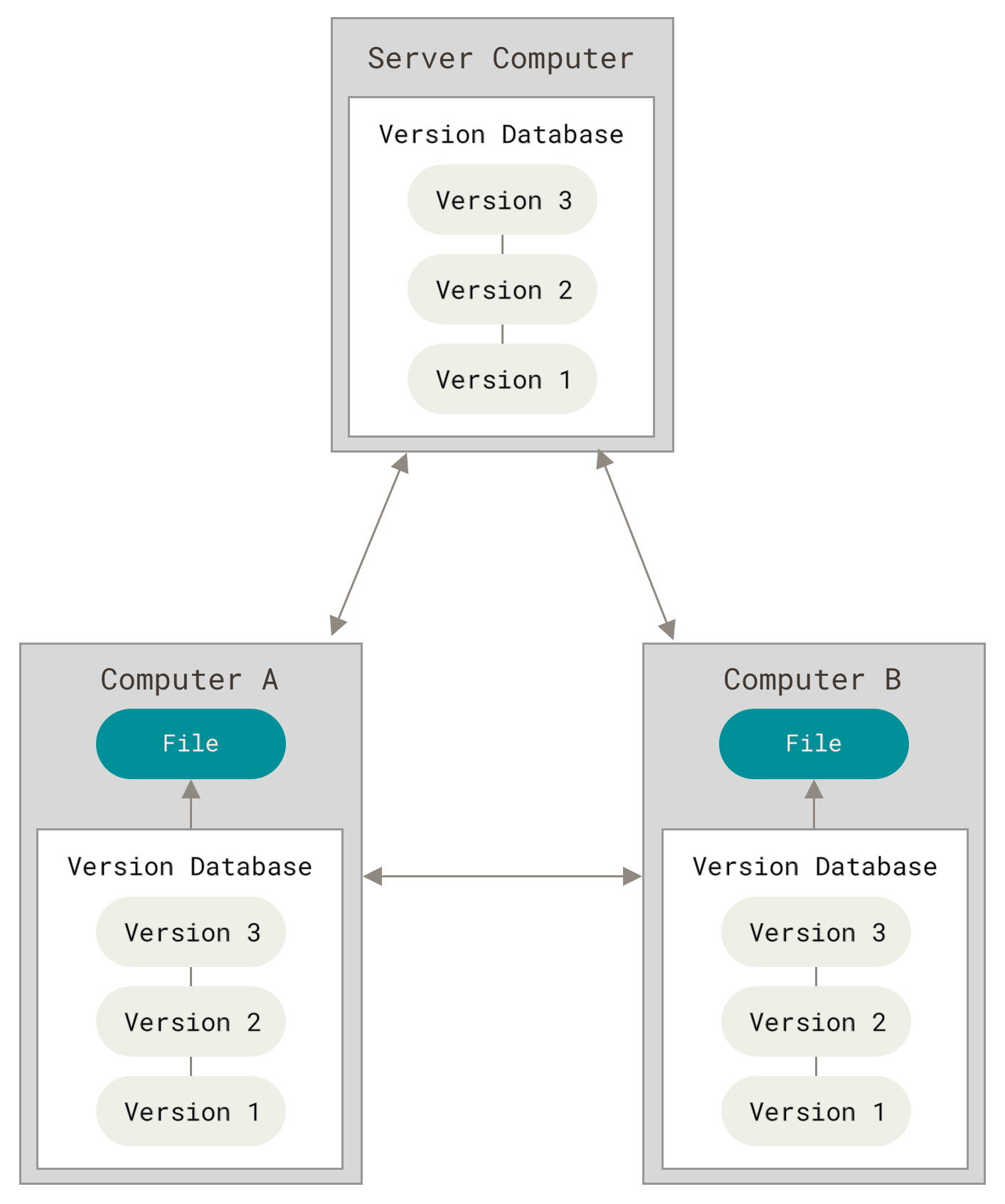
Sistemas de Control de Versiones Distribuidos
Los sistemas de Control de Versiones Distribuidos (DVCS por sus siglas
en inglés) ofrecen soluciones para los problemas que han sido
mencionados. En un DVCS (como Git, Mercurial, Bazaar o Darcs), los
clientes no solo descargan la última copia instantánea de los archivos,
sino que se replica completamente el repositorio. De esta manera, si un
servidor deja de funcionar y estos sistemas estaban colaborando a
través de él, cualquiera de los repositorios disponibles en los clientes
puede ser copiado al servidor con el fin de restaurarlo. Cada clon es
realmente una copia completa de todos los datos.
Figure 3. Control de versiones distribuido.
Además, muchos de estos sistemas se encargan de manejar numerosos repositorios remotos con los cuales pueden trabajar, de tal forma que puedes colaborar simultáneamente con diferentes grupos de personas en distintas maneras dentro del mismo proyecto. Esto permite establecer varios flujos de trabajo que no son posibles en sistemas centralizados, como pueden ser los modelos jerárquicos.
No hay comentarios.:
Publicar un comentario